Tiered model routing: cheap-first, escalate on demand, and the AI IDE default nobody ships
AI IDE users burn premium credits on tasks a smaller model would have solved in two seconds. The fix isn't a smarter model — it's a router that runs the cheap tier by default and only escalates when the cheap tier flunks a verification step. Here's how that should be wired into the IDE, and what teams build today to approximate it.
Open the credit-usage panel of any AI coding subscription and look at what burned the credits. Most of it isn't the hard refactor or the architectural debate. It's a hundred small tasks the IDE quietly sent to the strongest model because the strongest model is the default: renaming a variable, formatting a block, generating a docstring, finishing an import, suggesting a regex. None of those needed a frontier model. All of them got one.
The pattern is consistent across r/ClaudeAI, r/cursor, r/AICodeAssist and the Cody / Composer / Windsurf forums. Users do the math on their monthly bill, realise they're paying premium-tier rates for completions a 3B-parameter model would have nailed, and ask the same thing: can the IDE route — try the cheap tier first, only escalate when escalation is justified, and surface the routing decision so trust can be built?
The answer is yes, this is the right design, and almost no IDE ships it by default. Here's the shape of the system, the four signals that make routing trustworthy, and what teams hand-build today to approximate it before their vendor catches up.
Why default-strongest is the wrong default
IDEs ship default-strongest because it's the safest single decision. It maximises out-of-the-box completion quality, minimises support tickets about "the AI is dumb," and the user pays per-token so the IDE's incentive is fine. Default-strongest is right for the trial week and wrong for the steady-state user who is now writing the cheque every month.
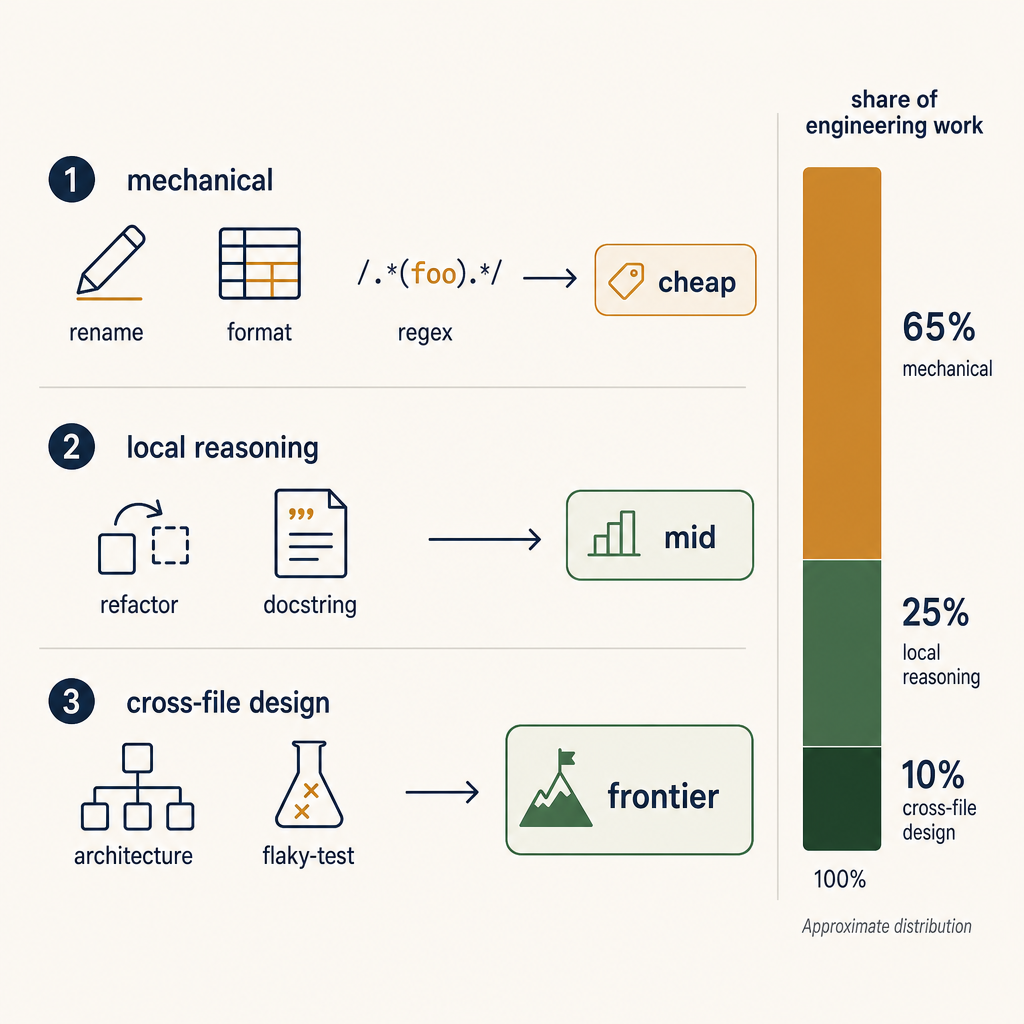
The steady-state user has three categories of task and they're not the same:
- Mechanical — variable rename, format, autocomplete, regex generation, simple test scaffolding. ~60–70% of all tool calls in a typical session. A 7B–13B class model handles these correctly at >95% rate.
- Local reasoning — refactor inside one file, infer the next method body, write a docstring that references the function's actual logic, generate a small fixture. ~20–30%. A mid-tier model (a frontier model from one generation ago, or a current-tier "small" model) handles these correctly at >90%.
- Cross-file or design reasoning — "refactor this pattern across the codebase," "why is this test flaking," "is this migration safe." ~5–10%. Frontier model territory. Anything cheaper degrades sharply.
Default-strongest treats all three buckets the same. The user is paying 10× for the 60% of work that didn't need 10× model. That's the cost the routing system recovers.
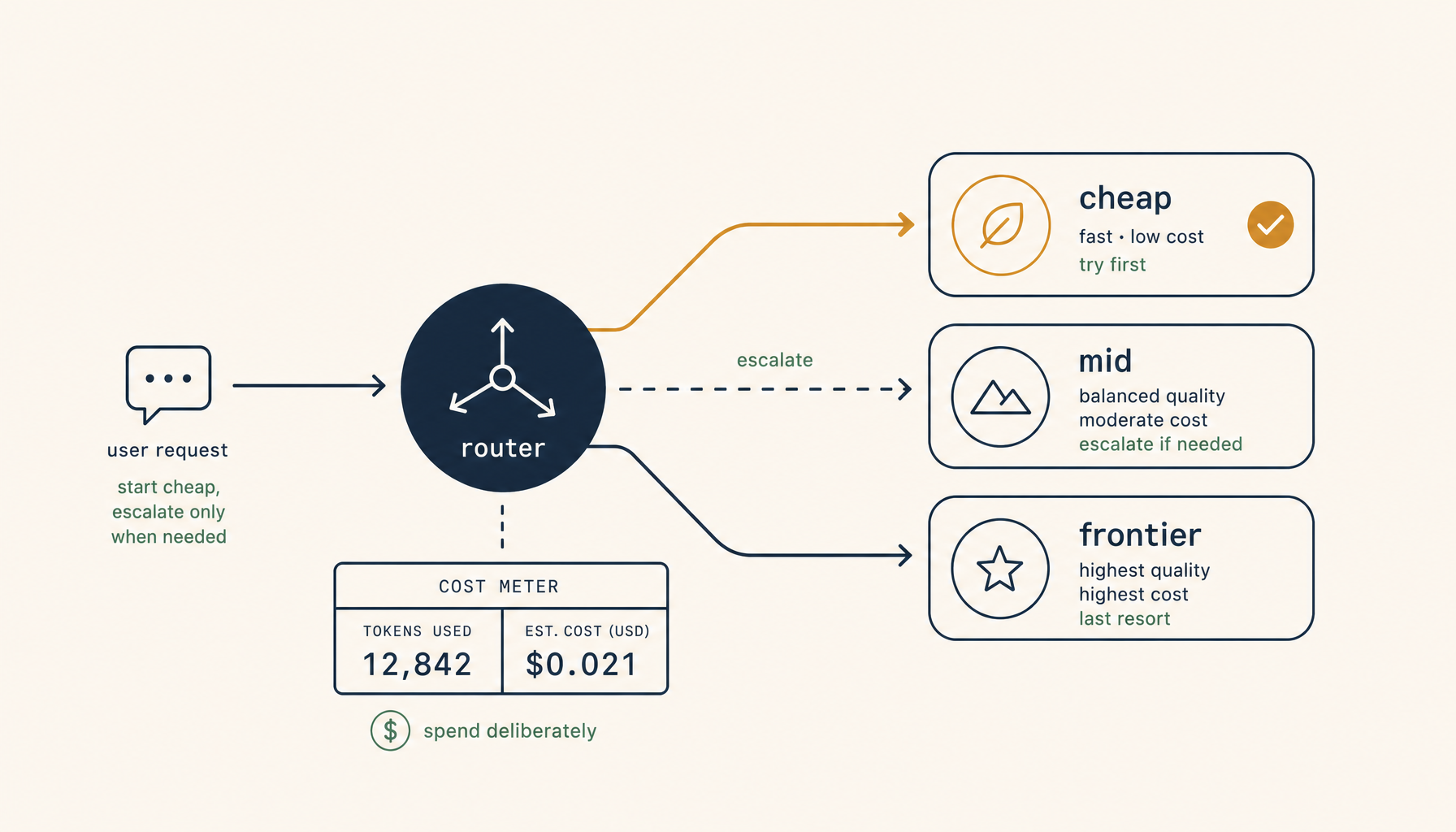
The routing decision
A tiered router is a thin layer between the IDE's request and the model API. It picks a tier per request based on cheaply-computable signals, runs the request, and conditionally escalates if the result fails a verification step. Three concepts make the design work.
Concept 1 — start cheap, verify, escalate
For every request, the router tries the cheap tier first. The response runs through a fast verifier — does the suggestion compile, does the patch apply cleanly, do the changed tests still pass, does the type-checker complain. If verification passes, ship it; the user never sees the routing happen. If verification fails, escalate to the next tier and retry. If the mid tier also fails verification, escalate to the frontier tier.
Most real-world traffic terminates at the cheap tier. A non-trivial fraction escalates once. A small fraction escalates twice. The total tokens spent is dominated by the long tail of frontier-tier requests, not by the volume of cheap-tier ones — which is the whole point.
The verifier is the part that has to be cheap. If you spend 200ms verifying every completion, the routing system feels slow. If you spend 5–20ms running a quick npx tsc --noEmit against the changed file, or running the relevant unit tests, the verification dominates only when something is actually wrong. Investing in the verifier is investing in the entire economics of the system.
Concept 2 — task-class hints from the IDE
The IDE already knows what kind of task the user is doing — there's a different tool path for autocomplete, for chat, for refactor, for inline edit. The router uses those hints to skip tiers when justified.
- Autocomplete — always cheap tier. Latency matters more than quality; the user types
cagain if the suggestion is wrong. - Single-line inline edit — cheap tier with verification.
- Multi-file refactor or chat thread > 8 turns — skip the cheap tier; start at mid tier.
- Explicit user request for a "think hard" mode — frontier tier from the start, no escalation needed.
None of this requires the model to classify the task. The IDE knows. Wiring those hints into the router is a 50-line change.
Concept 3 — caching the escalation decision per file
When the router escalates twice on the same file or function, the third request shouldn't re-do the cheap-tier attempt. Cache the escalation decision per file (or per repo-area) for a short TTL — 15 minutes is plenty. Subsequent requests in the same file start at the tier the router learned was sufficient last time.
This is what gets the cost down from "router pays for two failed cheap attempts before every win" to "router pays once to learn the file is hard, then routes correctly for the rest of the session."
The four trust signals
A router users trust shows them four things, none of them buried:
- Which tier ran this request. A small chip or icon next to the suggestion, not a stats page three menus deep.
- Why this tier was picked. Two words is enough: "cheap tier — autocomplete" or "mid tier — refactor, escalated from cheap."
- The per-request cost. Tokens in, tokens out, dollar value. Sub-cent values shown as such.
- A one-keystroke override. "This was wrong, escalate now" —
⌘⏎or similar. The router learns from explicit overrides, not from silent dissatisfaction.
Without those signals the user can't develop a mental model of when the router is working and when it's misfiring. With them, after a couple of days, the user stops looking — which is the goal. Trust is the system not requiring your attention.
What teams build today
The vendors will get here eventually. Teams that don't want to wait have three viable approximations. 1devtool ships a version of this routing layer as a first-class feature, but if you'd rather build it yourself, the three approximations below cover most of the ground.
Approximation 1 — a local proxy with a routing config
Run a small process locally (a few hundred lines of Python or Node) that exposes an OpenAI-compatible endpoint, classifies incoming requests by task hint and prompt length, and forwards to whichever upstream model the routing config picks. Point the IDE at the proxy. Verification is optional in this version — even the routing decision alone, without escalation, recovers most of the cost gap.
This is the floor. It's also the version that's easiest to evolve into the full design once it's been running for a week and you've seen the actual task distribution.
Approximation 2 — a multi-key model gateway
Several OSS projects (9Router, LiteLLM, OpenRouter as a SaaS) act as multi-provider gateways with routing rules. Point your IDE's custom-model setting at the gateway and configure routing centrally. Less control than a hand-rolled proxy; far less code to maintain. Good fit if the IDE already supports OpenAI-compatible custom endpoints.
Approximation 3 — the simplest possible: two profiles, manually switched
If you don't want infrastructure, configure two named profiles in your IDE — "Cheap" (a fast small model for autocomplete + edits) and "Hard" (a frontier model for chat + refactor). Use a global keybind to switch. Hand-routing is worse than auto-routing, but it's strictly better than default-strongest and takes ten minutes to set up.
The cost recovery here is real even at the manual level — users who flip to the Hard profile only for hard tasks regularly report 60%+ credit savings without any quality drop they can feel.
The IDE feature that would close this
For IDE vendors reading this, the missing default is: start cheap, verify, escalate on failure, show the user what just happened, cache the escalation decision for the session. Five lines of product copy, five components in a UI, and one verifier-per-language pipeline.
The reason it hasn't shipped is the same reason most economic-defaults are mis-set in software — the product team's incentive doesn't line up with the user's wallet. The IDEs that win the steady-state market in the next year will be the ones that fix that mismatch and ship the right default. Until then, the work of routing falls on each team to do for themselves, in one of the three forms above.
The shape of the eventual win is clear. A routing layer that is invisible when it works, transparent when it matters, and trusts the IDE about the task class. The current default — every task gets the frontier — is a transitional artifact. Treat your monthly bill as the signal that the transition is over.