The Underrated DevOps Practice: Preflight Scripts That Prevent Regressions
Most teams discover preflight checks the same way: an outage. Here's the pattern, why it's so cheap, and what to put in yours.

Most teams discover preflight checks the same way: an outage. A deploy goes out, the new version crashes on startup because of a missing env var, the rollback takes ten minutes, and someone in the postmortem says "we should have checked for that before deploying." Two weeks later it happens again, and the same person says the same thing.
The fix is a preflight script. The pattern is dead simple, the value is enormous, and almost no team writes one until after they've been burned twice.
What a preflight script actually is
A preflight is a small, idempotent script that runs before you ship the change and verifies that the environment can support it. It exits 0 if everything's ready and non-zero if something's missing. That's the whole shape.
It's not a test suite. It doesn't run your code. It checks the conditions your code assumes:
- Required env vars are set and non-empty
- Required services are reachable
- The DB has the migrations the new code expects
- Disk has enough free space for the new artifact
- The user running the deploy has the permissions they need
- External APIs the new code calls are responding
A good preflight runs in under thirty seconds and gives you a clear line of output per check.
Why teams skip it
The argument against preflights is always the same: "We have tests. We have CI. We have monitoring. Why do we need another step?"
Because tests verify code behavior in a fake environment, CI verifies code behavior in a CI environment, and monitoring tells you AFTER something broke. None of those check the production environment immediately before deploy, which is where the most expensive failures hide.
The other reason teams skip it: writing a preflight feels like work that doesn't ship a feature. It does — it ships predictability. But that's a hard sell to a roadmap-driven planning meeting.
A minimal preflight in bash
Start with this. Add to it as you learn what breaks.
#!/usr/bin/env bash
# preflight.sh — run before any deploy
set -u # error on undefined vars
fail=0
check() {
local name=$1 status=$2
if [ "$status" -eq 0 ]; then
echo " ✓ $name"
else
echo " ✗ $name"
fail=1
fi
}
echo "== Environment =="
[ -n "${DATABASE_URL:-}" ]; check "DATABASE_URL set" $?
[ -n "${API_KEY:-}" ]; check "API_KEY set" $?
[ -n "${S3_BUCKET:-}" ]; check "S3_BUCKET set" $?
echo "== Connectivity =="
psql "$DATABASE_URL" -c "SELECT 1" >/dev/null 2>&1; check "Postgres reachable" $?
curl -fsS https://api.example.com/health >/dev/null; check "Upstream API reachable" $?
echo "== Disk =="
[ "$(df -m /var | awk 'NR==2 {print $4}')" -gt 500 ]; check ">500MB free in /var" $?
echo "== Migrations =="
expected=$(cat ./migrations/CURRENT)
actual=$(psql "$DATABASE_URL" -tAc "SELECT version FROM schema_migrations ORDER BY version DESC LIMIT 1")
[ "$expected" = "$actual" ]; check "DB at migration $expected" $?
[ $fail -eq 0 ] && echo "PREFLIGHT OK" && exit 0
echo "PREFLIGHT FAILED" && exit 1
Wire it into your deploy command:
./preflight.sh && ./deploy.sh
If preflight fails, the deploy doesn't start. The whole point.
What to add over time
Preflights are an organic artifact. You don't design them up front; you grow them by adding a check every time something would have been caught.
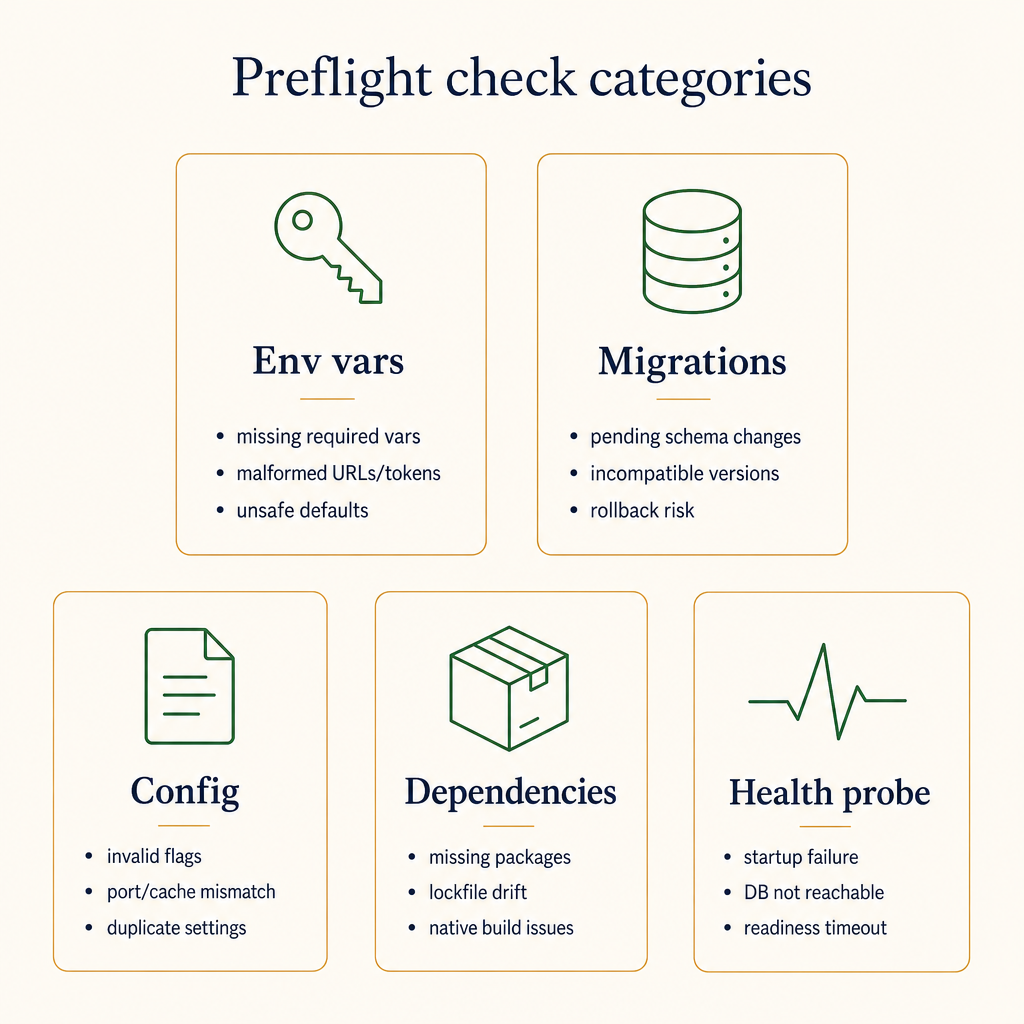
Group checks by what they're protecting against. Each category catches a different failure class.
Common additions after real incidents:
- Migration drift check. Compare expected migration version (committed in repo) to actual (in DB). The mismatch above is the simplest version. Catch this and you'll never wonder why your code can't find a column again.
- Dependency version check.
node --versionmatches.nvmrc,python --versionmatches.python-version. Catches half of "works on my machine." - TLS expiry.
openssl s_client -connect api.example.com:443 -servername api.example.com 2>/dev/null | openssl x509 -noout -enddateand parse the date. Lots of outages start as a quietly-expired cert. - Secret freshness. If you rotate API keys, check that the one in the env was last touched in the last N days.
- Outbound IP. Some services lock to specific IPs. Confirm
curl -s https://ipinfo.io/ipreturns what they expect. - Feature flag client connectivity. If the new code reads a flag, fail loudly if the flag service is unreachable.
Each addition takes ten minutes and pays back the first time it catches something.
Preflight vs postdeploy smoke test
These are different things and you want both.
| Preflight | Postdeploy smoke test | |
|---|---|---|
| When | Before deploy | After deploy |
| Purpose | Block bad deploys | Detect bad deploys |
| Scope | Environment | Application |
| If it fails | Don't deploy | Roll back |
A preflight protects you from environment drift. A smoke test protects you from code regressions. Together they catch >80% of the noise that pages people on a Friday.
Why this is a recurring ask
Talk to anyone who's recovered from a memorable production incident and they'll mention some version of "we should automate this check before next time." That feeling fades, then a different incident reminds them. The teams that capture it the first time are the ones with low-toil deploys; the teams that don't keep paying the same incident over and over.
Preflight scripts are the cheapest, highest-leverage piece of operational infrastructure most teams aren't writing.
Start with three checks. Add one per week. Your future on-call self will mail you cookies.
Related in the StoicSoft network
If you run monitoring, uptime checks, or alerting across self-hosted apps like the ones above, ServerCompass is the StoicSoft network's tool for wiring tiered severity, flap suppression, and low-noise alerts into a single dashboard.
If you work in AI-assisted coding, shared terminal sessions, or agent-driven shell workflows like the ones above, 1devtool is the StoicSoft network's tool for safer AI-assisted terminal work — shared sessions with auditing, preflight policy, and tiered model routing built in.