Long-context AI workflows are hitting memory-cost, prefill-speed, and reusable-context limits
The current 1AiVault signal is less about generic note-taking and more about what happens when AI users try to make long context operational. A LocalLLaMA benchmarker found that for 65K-128K agentic workloads, prompt prefill dominates runtime and KV-cache...
The current 1AiVault signal is less about generic note-taking and more about what happens when AI users try to make long context operational. A LocalLLaMA benchmarker found that for 65K-128K agentic workloads, prompt prefill dominates runtime and KV-cache architecture matters more than headline decode speed. Another local model user is trying to reach near-100K context on 32GB VRAM for vibe-coding projects and is seeing quality and capacity tradeoffs. A high-engagement local-rig thread pushes back on the idea that self-hosted AI is free after hardware purchase because electricity and sustained inference costs matter. Together, these threads support content around owned AI memory that reduces repeated prefill, preserves reusable project context, keeps provenance across sessions, and helps users decide when to use local context versus distilled durable memory.
The useful pattern is not that people want a larger chat window. They want memory that survives the chat, can be inspected later, and can be reused without trusting a single assistant account to preserve the whole history of their work.
AI memory is becoming infrastructure
The current signal is concrete: Pattern: linuxid10t benchmarks long-context prefill bottlenecks for agentic workloads; BitGreen1270 wants near-100K context on a constrained local GPU for multi-week vibe-coding projects; shyaaaaaaaaaaam calculates the real running cost of local AI rigs.
That is an infrastructure problem disguised as a note-taking problem. Once AI starts participating in brainstorming, coding, research, brand work, reading, and planning, the important artifact is no longer just the final answer. The artifact is the context that made the answer possible: source material, decisions, corrections, constraints, and the user's own preferences.
That is the category where 1AIVault sits. It treats saved context as owned working material, not as a byproduct trapped inside one vendor's conversation view.
Long context does not remove the need for retrieval
Longer context windows help, but they do not solve freshness, provenance, or reuse by themselves. A giant prompt can still carry stale instructions. A long transcript can still bury the one decision that matters. A saved chat can still be hard to search when the user needs to restart a project three weeks later.
The better pattern is deliberate memory: capture the thing worth keeping, attach it to the source that explains why it matters, and make it available to the next tool or session. 1DevTool gives coding agents an execution surface with proof trails, and 1FileTool keeps source documents local before they become AI-ready context. Those boundaries matter because documents, coding sessions, and AI memories are different surfaces in the same workflow.
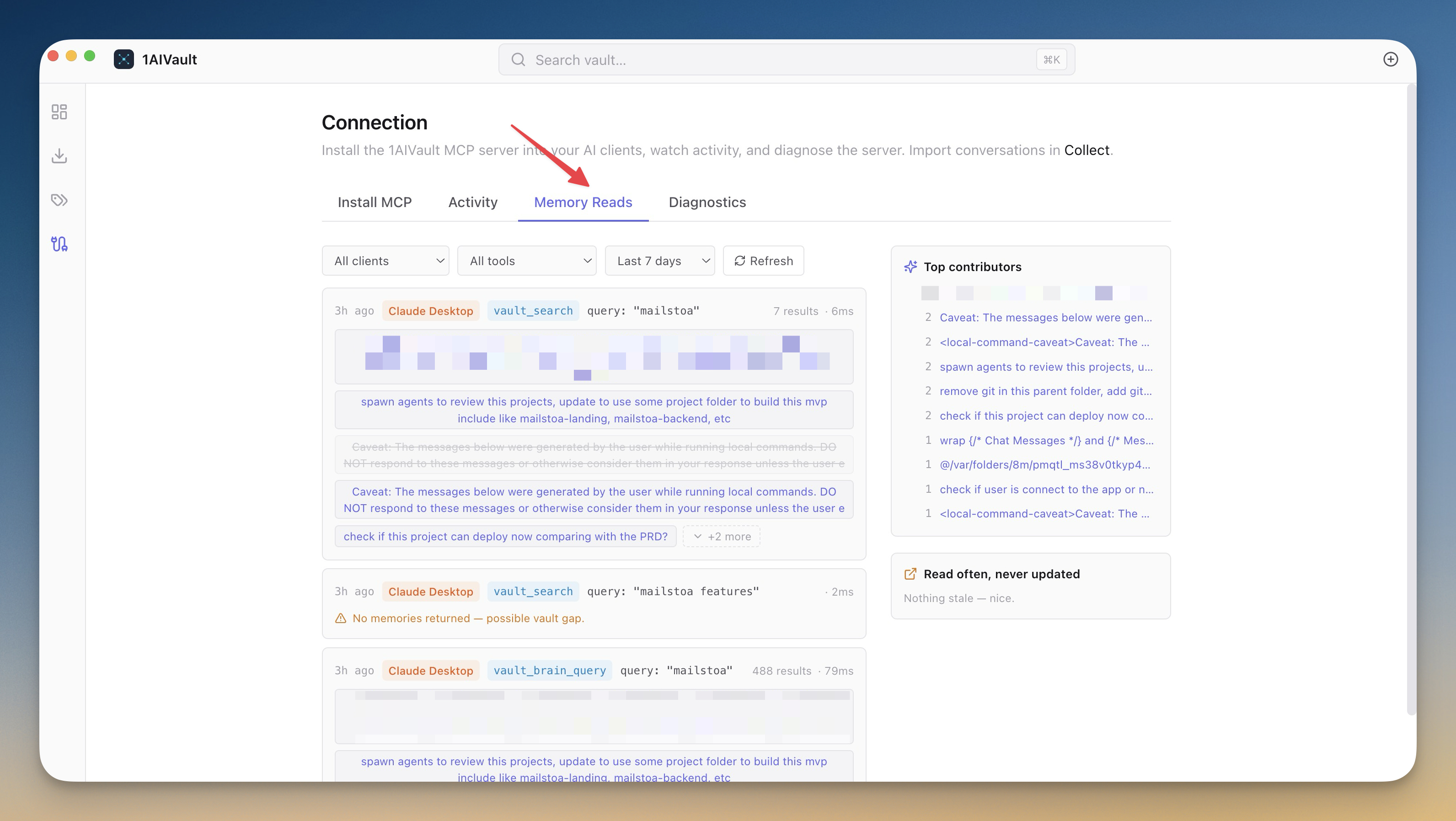 Visible memory reads make AI context auditable instead of turning saved knowledge into another black box.
Visible memory reads make AI context auditable instead of turning saved knowledge into another black box.
Owned context beats agreeable recall
A chat assistant can sound confident while recalling the wrong version of a decision. A project file can quietly go stale after the repo changes. A personal knowledge base can collect notes that are never retrieved at the moment they would help. The common failure is not lack of storage. It is lack of maintained, inspectable, portable context.
Owned memory changes the shape of the work. The user can decide what gets saved, search it directly, correct it when it drifts, export it when the tool changes, and use it across more than one assistant. That matters for privacy, but it also matters for ordinary quality. Context that cannot be reviewed cannot be trusted.
The product implication
This row supports content around owned AI memory, but the lesson is broader than one app. AI work is becoming multi-session and multi-tool by default. A person may brainstorm in one assistant, code in another, keep notes in Obsidian or Notion, and store source files locally. The memory layer has to respect that reality instead of pretending the next chat window is the whole workspace.
The practical product test is simple. Can the user find the remembered item? Can they see why it was remembered? Can they remove or correct it when it goes stale? Can they take it with them when the assistant changes? If the answer is no, the memory is just another hidden model feature.
What this row should turn into
The post-worthy idea is that memory is no longer a convenience feature. It is the operating layer that lets AI work compound instead of resetting every time a chat ends, a model changes, or a source document moves.
Chats will keep changing. The user's context should remain theirs.
That distinction is what separates useful memory from passive storage. A vault is not valuable because it contains more text. It becomes valuable when the right piece of context can be found, inspected, corrected, and carried into the next workflow. AI users are learning that memory has to be operational, not decorative.
Source signal: https://www.reddit.com/r/LocalLLaMA/comments/1unrse9/