Context-Window Management Is a Workflow Problem, Not a Model Problem
Long AI coding sessions degrade because the workflow around the model fails to manage context as a finite, allocable resource. Treat the window as a budget you plan, chunk, hand off, and reset on schedule.
You are ninety minutes into a feature. The agent suggests a refactor it already made an hour ago. It re-reads files it has read four times. It cheerfully proposes a change that contradicts the architectural decision you locked in at minute thirty. You stop, sigh, hit /compact, and watch quality drop another notch.
This is not a model failure. The model is doing exactly what it does: predicting from the tokens in front of it. What failed is the workflow around the model. The context window filled with stale conversation, half-applied diffs, and dead reasoning, and nothing in your loop took responsibility for managing it.
Treat the context window as a budget, not a buffer. That is the entire frame shift.
The mental model: context as an allocable resource
A context window is finite. Every token you spend on stale chat history, redundant file dumps, or rehashed reasoning is a token you cannot spend on the current task. Past a certain saturation point, attention degrades non-linearly. Models start hallucinating decisions, contradicting themselves, and confusing files. Cursor and Claude Code both expose this directly: long sessions get measurably worse, and not gracefully.
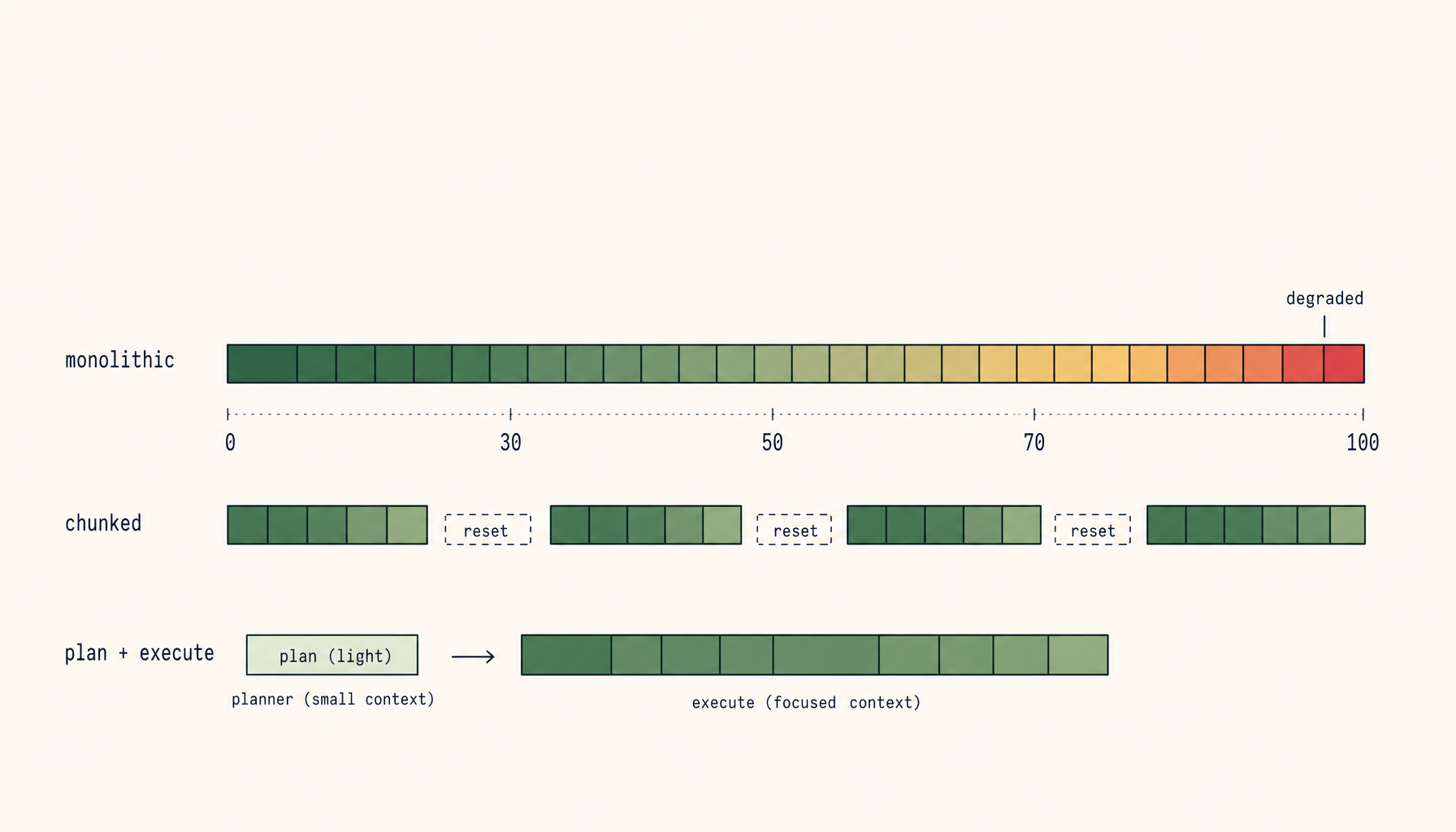
The naive approach is to fill the window until something breaks, then start over. The mature approach is to plan the budget before you start, allocate it deliberately, and reset on a schedule rather than on a crisis.
Three rules, then the patterns.
- Anything that fits in 30-50 percent of the window will produce reliable output. Anything that needs 70 percent or more will not.
- The cost of a fresh session with a good handoff is almost always lower than the cost of pushing a degraded session further.
- The agent cannot manage its own context. You have to.
Plan and execute, on separate agents
The most effective single change is to split your work between two distinct agent sessions.
The planner is broad and shallow. It reads the relevant code, talks through the architecture, considers tradeoffs, and writes a plan. It uses a cheap or fast model. Its job is not to ship code. Its job is to produce a document that can be handed off.
The implementer is narrow and deep. It receives the plan, reads only the files the plan names, and writes the diff. Its context is not polluted with rejected ideas, exploration, or architectural debate. It does one thing.
A good plan doc looks like this:
## Goal
Add rate limiting to the /api/upload endpoint.
## Files to touch
- src/middleware/rate-limit.ts (new)
- src/server.ts (wire middleware)
- src/middleware/__tests__/rate-limit.test.ts (new)
## Decisions already made
- Token bucket, in-memory only (Redis comes later)
- 10 req/min per IP
- Return 429 with Retry-After header
## Out of scope
- Distributed rate limiting
- Per-user limits
## Open questions
- None. Implementer should not deviate.
The implementer reads that, opens three files, writes a diff. No exploration phase. No re-deciding what was already decided. The context stays clean because the scope is closed.
Chunk to fit, not to finish
A common failure mode: you ask for "the whole feature" and the agent gamely tries, dumping fifteen files into context, half-implementing each, losing track of which version of which function it was working on.
The fix is to chunk by what fits, not by what completes the feature. If a unit of work needs more than 30-50 percent of the window to do cleanly, split it. The split points are usually obvious in retrospect: schema first, then API, then UI. Migration first, then code that uses it. Tests first, then implementation.
Each chunk should be self-contained enough that you could hand it to a fresh session with a one-paragraph brief. If you can't, the chunk is too big.
This is not the same as making tasks artificially small. A 200-line diff across three files is fine if the agent can hold all three files plus your conversation in budget. A 50-line diff across twelve files is not, because the agent has to load all twelve.
Summary handoffs instead of session continuity
When you hit the end of a productive session, do not just close it. Do not rely on /compact either - compaction is lossy in unpredictable ways and tends to discard exactly the architectural decisions you needed to keep.
Instead, ask the agent to write a structured handoff before you end the session. Something like:
Write a HANDOFF.md with:
- Current state: what's done, what's in progress, what's untouched
- Decisions made this session (with reasoning)
- Files changed and why
- Next 3 concrete steps
- Open questions for the next session
- Anything I should NOT redo
You read this. You correct it. You save it. The next session opens cold, reads HANDOFF.md as its first action, and primes from a clean 500-token summary instead of a 50,000-token chat replay. The new session does not inherit the old session's confusion. It inherits the old session's conclusions.
This is the single highest-leverage habit on this list. Most people do not do it because it feels like overhead. It is not overhead. It is the work.
Budget the prompt explicitly
Modern agents respond well to explicit context-management instructions. Tell them what matters.
You have approximately 100K tokens of working context. Prioritize:
1. The plan in PLAN.md (must stay in context)
2. The files listed in the plan (read once, refer back)
3. Test output from the most recent run
Do NOT re-read files you have already read this session.
Do NOT dump entire directories.
If you find yourself wanting to read more than 5 files, stop and ask.
This sounds bureaucratic. In practice it cuts context bloat substantially because the agent now has explicit permission to refuse the kind of expensive, low-value reads it would otherwise default to.
A related trick: when you hand the agent a large file, tell it which lines matter. "Read auth.ts, focus on lines 80-140, the rest is unrelated." The agent will still load the whole file but it will reason about the right slice.
Scratchpad files instead of conversational state
Anything important that the agent figures out should be written to disk, not held in conversation. A NOTES.md, a DECISIONS.md, a comment block at the top of the file - whatever fits the project. The principle is simple: conversation is volatile, files are durable.
This matters most for two things. First, decisions: "we chose X over Y because Z" should live in a file the next session can read, not in a chat the next session will not see. Second, intermediate state: if the agent computes a complex mapping or derives a non-obvious pattern, dump it to a scratchpad. You can throw the scratchpad away when the feature ships. While the work is in flight, it is cheaper to read than to re-derive.
Claude Code does this naturally with its file-editing tools. Cursor users often have to nudge it explicitly. Either way, the agent that writes its thinking down outperforms the agent that holds it in conversation.
Recognize the hard-reset triggers
You should reset the session, not push through, when you see any of these:
- The agent suggests a change it already made.
- The agent contradicts a decision you locked in earlier.
- The agent confuses two files (mentions content from
a.tswhile editingb.ts). - The agent's diffs start getting smaller and more conservative for no reason.
- You start writing longer and longer prompts to fight the drift.
These are not signs to try harder. They are signs the window is saturated and the model is running on degraded attention. Save state, write a handoff, start a new session. The five minutes you spend resetting will save you thirty minutes of fighting a confused agent.
What not to do
A short list of things that look like context management but make it worse.
Long /compact chains. Compaction is a lossy summary of a lossy summary. Two compactions in, you have a session whose understanding of the work bears only superficial resemblance to reality. Use compact once, sparingly, and treat it as a last resort before a clean reset.
Mass file dumps. Pasting twenty files in to "give the agent context" almost always degrades output, because relevance per token collapses. The agent now spends its attention on noise. Read fewer files, more deliberately.
"Just paste the whole repo." Modern repos exceed any context window worth talking about. Tools that paper over this with retrieval are only as good as their retrieval, which on a working codebase is rarely good enough. If you find yourself wanting to do this, the real answer is to write a better plan that names the specific files that matter.
Treating model upgrades as a substitute for workflow. A larger context window does not fix any of the failures above. It just lets you fail more expensively before noticing. The teams getting the most out of Cursor and Claude Code are not the ones with the longest context - they are the ones who treat context like the scarce resource it is, even when it is technically abundant.
The model is not the bottleneck. Your workflow is. Plan the budget, chunk to fit, hand off in writing, reset on schedule. The session that ships the feature is almost never the session that started the feature - and that is the point.
Related in the StoicSoft network
If you work in AI-assisted coding, shared terminal sessions, or agent-driven shell workflows like the ones above, 1devtool is the StoicSoft network's tool for safer AI-assisted terminal work — shared sessions with auditing, preflight policy, and tiered model routing built in.
From across the StoicSoft network
Hand-curated reads on the same topic from sister sites in the StoicSoft family.
- 1FileTool5 min read
Watch Any Folder. Process Files as They Arrive.
The Folder Monitor watches any folder and automatically applies a tool to every new file — compress, convert, strip metadata — in the background, without you having to touch the tool each time.
Read on 1filetool.com  1FileTool5 min read
1FileTool5 min readEdit PDFs Visually and Save Your Tool Settings as Presets
1FileTool now has a visual PDF editor — see pages as you rearrange, annotate, and watermark. Plus tool presets: save your settings once and apply them in one click, across every tool.
Read on 1filetool.com