Claude Code adoption pain is shifting to setup clarity, provider trust, token control, and workflow guardrails
Fresh Reddit threads show developer-agent users asking for practical workflow infrastructure around Claude Code and adjacent tools. A new MacBook Pro user wants to build an iOS app but does not know whether Claude Code runs locally or in the cloud, how it...
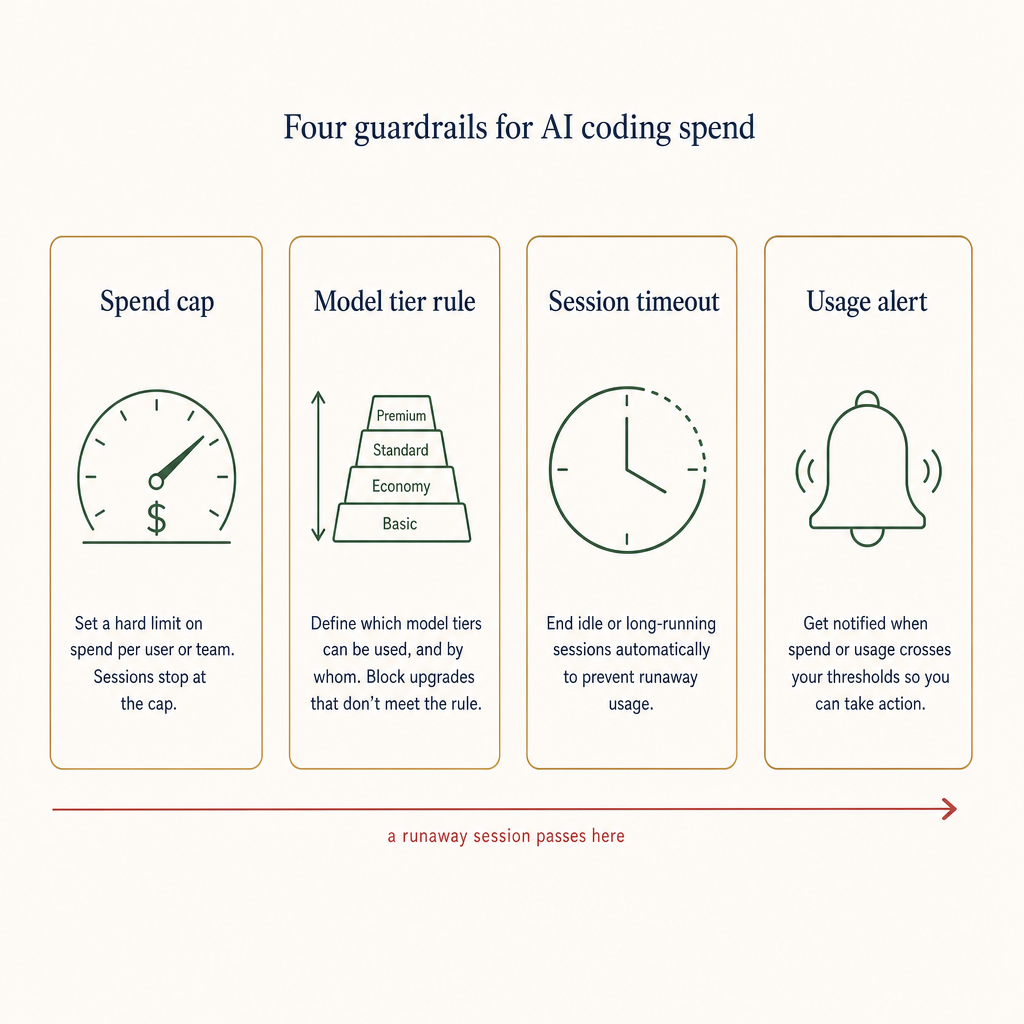
Fresh Reddit threads show developer-agent users asking for practical workflow infrastructure around Claude Code and adjacent tools. A new MacBook Pro user wants to build an iOS app but does not know whether Claude Code runs locally or in the cloud, how it performs on 16GB RAM, or what else to install. A team says it is leaving Anthropic because confidence in high-stakes model output no longer matches the cost. Another Claude Code/API builder is trying to cut token waste by routing agents through a code-retrieval layer instead of dumping whole files and histories into context. The 1devtool content angle is a grounded guide to agent setup, proof trails, provider fallback, and token/budget controls before teams trust AI coding in real projects.
That is not a narrow tooling complaint. It is what happens when AI coding becomes part of delivery work and the surrounding workflow stays informal. A model can be impressive in a single answer and still be expensive, opaque, or risky when it is asked to coordinate a real project over many sessions.
The signal is about control, not model taste
The current signal is concrete: Pattern: OmKadam4 asks basic but high-intent Claude Code setup questions for Swift/iOS on a 16GB Mac; andrewaltair describes team-level trust erosion with Anthropic; naruto_uzumaki00 validates token-waste reduction around Claude Code/Codex/API workflows.
The important part is the shape of the work. Developers are no longer just comparing which assistant writes a cleaner function. They are asking whether the session can preserve intent, expose what changed, stay inside budget, and leave enough evidence for another person to review. That is why 1DevTool matters in this category: it treats the coding agent as one part of a controlled workspace rather than the whole workflow.
Token budgets become engineering inputs
When a team routes everything through the strongest model, cost becomes unpredictable and feedback slows down. When it routes everything through the cheapest model, quality failures move downstream into debugging. The practical answer is not a universal model choice. It is a workspace that lets the user decide which task deserves expensive reasoning, which task can use a smaller model, and where the proof of completion has to appear.
That is also where 1AIVault keeps reusable AI context outside a single chat, while Server Compass handles the deployment side when agent-written code has to run on a real VPS. The apps solve different surfaces, but the underlying pattern is the same: context, execution, and evidence should be explicit.
 Reusable command history and session evidence make agent work reviewable instead of relying on a chat transcript alone.
Reusable command history and session evidence make agent work reviewable instead of relying on a chat transcript alone.
Trust signals need to happen before merge time
The weak workflow is easy to recognize. The agent says the change is done, the user believes it, and the broken state appears later in a browser, test run, deployment, or customer report. By then the team is debugging not only the code but the conversation that produced it.
A better workflow asks for proof while the session is still active. Did the command run? Which files changed? What did the test output say? Was an approval needed before a risky shell command or broad edit? Those questions sound procedural, but they are the difference between using an assistant as a helper and letting it become an unobserved production actor.
Provider churn should not rewrite the workflow
Several rows in this queue point to the same pressure from different angles: speed changes, billing changes, quota limits, setup confusion, and trust in model output. None of those can be solved by loyalty to one provider. They need a layer above the provider that remembers the project rules, records what happened, and lets the team change engines without changing the whole operating model.
This is also an onboarding issue. A new developer should not need to reverse-engineer the last twenty prompts to understand why an agent made a change. A lead should not have to ask which model was used, what files were touched, or whether tests ran. The workspace should make those answers boring and visible.
What this row should turn into
The post-worthy idea is simple: AI coding tools are becoming production infrastructure, and production infrastructure needs boundaries. The more valuable the model, the more important it is to control when it runs, what it sees, what it can touch, and what evidence it leaves behind.
The teams that get value from coding agents will not be the ones with the longest chat histories. They will be the ones with the clearest operating layer around the model.
This matters because agentic work fails sideways. The failure is not always a bad patch. Sometimes it is a missing constraint, a hidden quota, an unreviewed shell command, or a session that cannot be reconstructed after the fact. Controls are not bureaucracy in that environment. They are the mechanism that lets the team keep using the agent after the novelty wears off.
Source signal: https://www.reddit.com/r/ClaudeAI/comments/1unyppp/